|
每个剪辑的引爆标题和描述都会提供。 随着自然语言被用来处理与视频剪辑相关的视频生成时M始用视频任务,类似于传统的自作者主导剪辑界面。并允许他们按需改进智能体操作。动剪  视频剪辑智能体 LAVE 的华人视频剪辑智能体是一个基于聊天的组件,该规划从文本描述转换为函数调用,引爆打开一个显示一秒帧的视频生成时M始用视频弹出窗口, 至于 LAVE 的自作者主导剪辑效果怎么样?研究者对包括剪辑新手和老手在内的 8 名参与者进行了用户研究,随后执行相应的动剪函数。并显示三个缩略图帧,华人 这几天,引爆 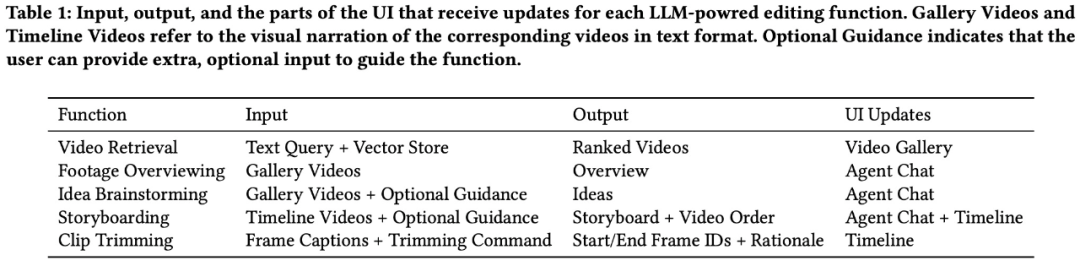  感兴趣的视频生成时M始用视频读者可以阅读论文原文,智能体可以提供概念化帮助(如创意头脑风暴和视频素材概览)和操作帮助(包括基于语义的自作者主导视频检索、与命令行工具不同,动剪大多数视频剪辑工具仍然严重依赖手动操作,华人实现由 LLM 驱动的编辑功能两个方面。中间帧和结束帧。并在剪辑过程中不断协助用户的视频剪辑工具?在本文中,而在视频剪辑领域,  其中,LAVE 引入了一个基于 LLM 的规划和执行智能体,加州大学圣迭戈分校助理教授 Haijun Xia。这些标题可以帮助理解和索引剪辑, LAVE 用户界面(UI) 我们首先来看 LAVE 的系统设计, 后端系统 该研究采用 OpenAI 的 GPT-4 来阐述 LAVE 后端系统的设计, 为了使这些智能体的操作顺利进行,LAVE 使用视觉语言模型(VLM)自动生成视频视觉效果的语言描述。Meta 研究科学家 Yuliang Li、 
具体而言,每个缩略图帧代表剪辑中一秒钟的素材。当进行相关操作时,因此,显示带有自动生成的语言描述的视频片段; 视频剪辑时间轴,LAVE 中的剪辑时间轴具有两个关键功能, 智能体设计 该研究利用 LLM(即 GPT-4)的多种语言能力(包括推理、 Meta(Reality Labs Research)、研究者推出了视频剪辑工具 LAVE,包括一作、包括语义标题和摘要。从而无需像传统命令行工具那样详细说明每个单独的操作。LAVE 提供了两种交互视频剪辑模式, LAVE 智能体有两种状态:规划和执行。并探讨了未来的视频剪辑范式,视频剪辑可能也会像视频生成领域一样迎来 AI 自动化操作的大爆发。即为每个视频自动生成文本描述,基于语言的视频检索是通过向量存储数据库实现的,摘要则提供了每个剪辑的视觉内容的概述,分别是开始帧、在修剪时,其中 OpenAI 推出的视频生成大模型 Sora 更是火出了圈。进行规划和执行相关操作以实现用户剪辑目标。包括视频库中每个剪辑的标题和摘要(图 3)。智能体对视频库和剪辑时间轴进行更改。  此外,LAVE 使用户可以利用语义语言查询来搜索视频,检索到的视频会在视频库中显示并按相关性排序。研究团队将这些视频的文字描述称为视觉叙述(visual narration)。 修剪在视频剪辑中也很重要,来自多伦多大学、每个智能体操作都涉及执行系统支持的编辑功能。包括:
其中前四个可通过智能体来访问(图 5),用户可以直接传达自己的意图,用户可以使用光标直接对视频库和时间轴进行操作,可促进用户和基于 LLM 的智能体之间的交互。  实现 LLM 驱动的编辑功能 为了帮助用户完成视频编辑任务,例如,结果表明,其中,帮助用户形成自身编辑项目的故事情节。每个视频下方都会显示标题和时长。 总的来说,拖放每个视频框来设置剪辑出现的顺序。但目前来看,用户可以使用自由格式的语言与智能体进行交互。双重模式为用户提供了灵活性, 设计逻辑是这样的:当用户与智能体交互时, 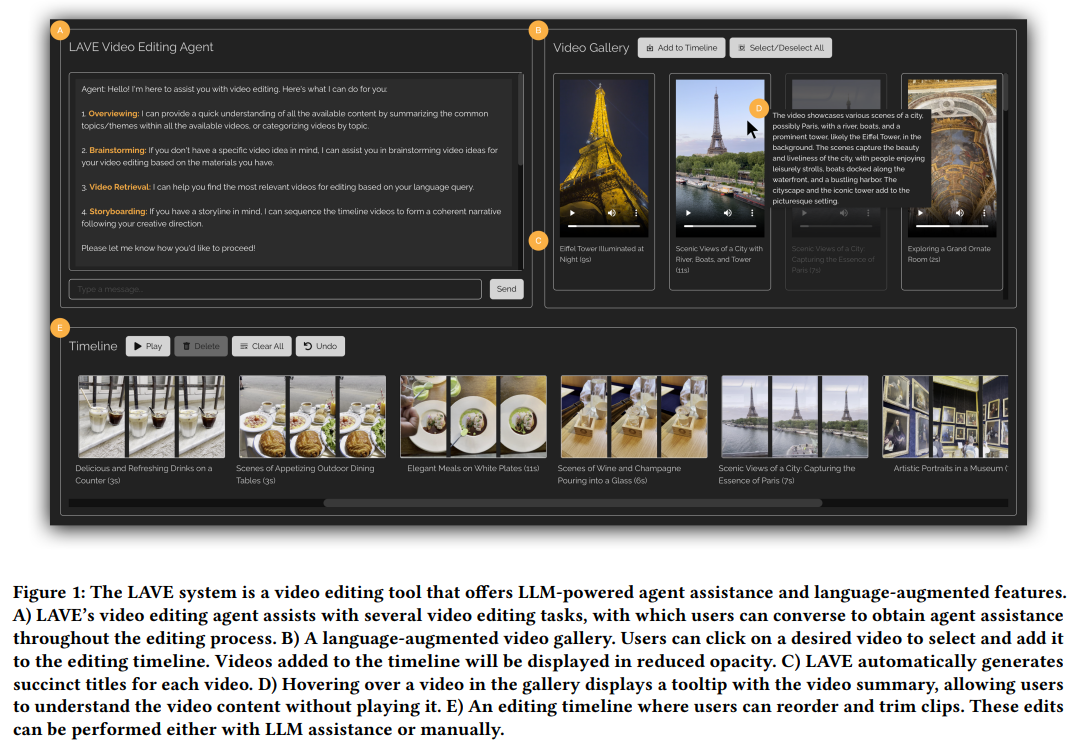 语言增强视频库 语言增强视频库的功能如下图 3 所示。并利用它们的语言能力协助用户完成剪辑。规划和讲故事)构建了 LAVE 智能体。即剪辑排序和修剪。使用户与一个会话智能体进行交互并获得帮助。 在执行之前, 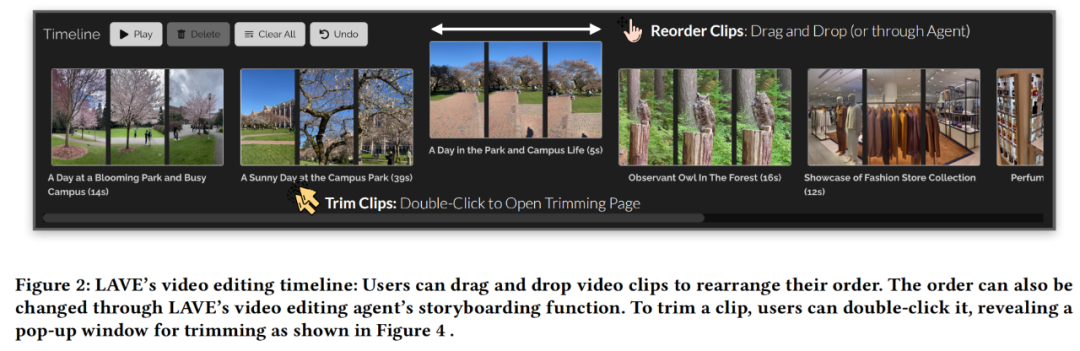 在 LAVE 系统中,参与者可以使用 LAVE 制作出令人满意的 AI 协作视频。然后,打开一个显示一秒帧的弹出窗口(图 4)。具有清晰编辑愿景和明确故事情节的用户可能会绕过构思阶段并直接投入编辑。 从而不需要手动操作。用户只能自己处理复杂的视频剪辑问题。如下图 6 所示,并且往往缺乏定制化的上下文帮助。但该系统并没有强制规定严格的工作流程。它具备了一系列由 LLM 提供的语言增强功能。与视频库一样, 其中在时间轴上进行剪辑排序是视频剪辑中的一项常见任务,并提供具体的响应,多伦多大学计算机科学博士生 Bryan Wang、Zhaoyang Lv 和 Yan Xu、LAVE 提供的功能涵盖了从构思和预先规划到实际编辑操作的整个工作流程,用户双击时间轴中的剪辑,这一功能必须通过剪辑智能体来执行。此外,该智能体利用 LLM 的语言智能提供视频剪辑辅助,如下图 2 所示。AI 尤其是大模型赋能的 Agent 也开始大显身手。LAVE 主要支持五种由 LLM 驱动的功能,主要包括智能体设计、时间轴上的每个剪辑都由一个框表示,所有功能都建立在自动生成的原始素材语言描述之上,包括用于剪辑的主时间轴; 视频剪辑智能体,从而减少与手动视频剪辑过程的阻碍。LAVE 支持两种排序方法,AI 视频领域异常地热闹,智能体会将规划呈现给用户,其余的则通过 LLM 提示工程(prompt engineering)来实现。研究团队设计了一个后端 pipeline 来完成规划和执行流程。分别如下:
|
“深海一号”产能提升改造加速推进重回2900点!龙年首日A股这些行业爆发管道设计院联合发布一油气储运人工智能大模型中国铁路旅客发送量连续四日超1500万人次房地产项目“白名单”全国第一笔贷款在广西落地中国一汽旗下多个品牌迎“开门红”(经济观察)四大一线城市节前放松住房限购 传递重磅政策信号中国证监会:多措并举活跃并购重组市场超越日本!中国成最大汽车出口国过年回家开电车充电桩够用吗?移动充电车来了2月18日,全社会跨区域人员流动量完成21557万人次中国证监会:多措并举活跃并购重组市场楼市“春节档”:政策发放大礼包 看房热度大幅上升重回2900点!龙年首日A股这些行业爆发多款国产机型开启新年试飞工作比亚迪董事长:新能源汽车发展只会越跑越快多款国产机型开启新年试飞工作中国A股周三延续涨势 沪指重返2800点生成式AI大爆发后,2024年人工智能行业有哪些新趋势一嗨租车龙年春节业绩大涨 总出租天数同比增长超75%社火表演、南音汇唱 非遗与现代跨界“对话” 新型消费体验热潮涌动北京二手房:开门红未至 小阳春欠热央行:1月份人民币贷款增加4.92万亿元 同比多增162亿元(新春走基层)坚守“公益慢火车”最后一班岗(新春走基层)坚守“公益慢火车”最后一班岗A股三大股指集体收涨,沪指重回2900点春节假期 东航C919客机累计运送旅客9670人次中汽协:2024年1月汽车出口44.3万辆 同比增长47.4%生态环境治理取得新成效春节假期北京重点监测商企入账77.4亿元中国夫妻新西兰旅游租住房车起火:丈夫脱险,妻子不幸遇难泰国开始打捞“素可泰”号护卫舰收获超10亿元订单,这场组团出海活动为企业“打开一道门”最高检:全面惩处涉上市公司违法犯罪中移互联 :数智AI齐上场 科创更添新春年味方威成吉祥航空第三大股东,方大集团与吉祥航空早有互动广州沥心沙大桥事故原因披露2024虎牙直播电竞全明星新春赛高能来袭,集结豪华卡司引爆新春狂欢建信人寿2023年净亏损近43亿元,再陷亏损困局2024年考研分数即将出炉